Async I/O Is Not Enough
For the past few months, I’ve been exploring Go. Having done quite a bit of grueling work shaving off milliseconds from Python web apps, I’ve found Go to be incredible. You can schedule dirt cheap concurrent operations — simply by adding go in front of a function call — and achieve true parallelism across cores.
Python’s asyncio tasks are also dirt cheap, which is especially useful for spawning tons of I/O operations (like DB calls for clients). However, unlike Go, they still pose an issue for web applications. When: a) latency is critical — horizontal scaling does not optimize single request duration, and b) there is an ever-growing amount of Python processing code scattered across the application, native extensions would be an overkill.
For CRUD apps, these constraints are somewhat less relevant, but they are quite typical for data science applications. Go shines in these scenarios, whereas asyncio is not a panacea. Why? Concurrency != parallelism. Single-threading by design itself. And thanks to our dear friend, the GIL.
I will illustrate with examples below how the issue eventually creeps in and how recent advances in No-GIL are highly promising in addressing it.
We’ll walk through a toy benchmark for an ML model-serving application. It retrieves features from various sources (e.g., a feature store) and performs some post-processing. We skip inference for simplicity.
1. Serial
Our initial application fetches features from 1 to 32 sources. We’re starting with a fully I/O bounded implementation. Assume the application does not perform any post-processing, so no meaningful CPU work for now.
def prepare_feature_batch_serial(preprocessing: bool = False, fraction_of_io: float = 0.0):
features = requests.get(f"https://httpbin.org/delay/1").json()
def perform_serial(num_feature_batches: int, fraction_of_io: float):
for _ in range(num_feature_batches):
prepare_feature_batch_serial(preprocessing=True, fraction_of_io=fraction_of_io)
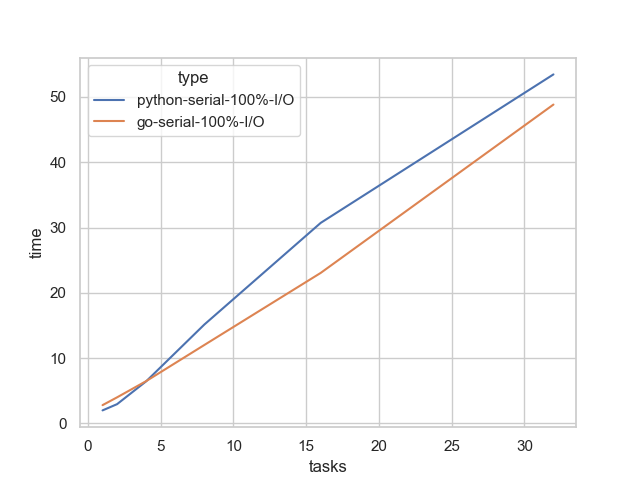
As expected, since our implementations are not concurrent, the total duration increases linearly, sharply. Go is a bit faster, but insignificantly.1
Both implementations above suffer from blocking I/O. Let’s see how we can alleviate this, both in Go (natively) and in Python (asyncio).
2. Non-blocking I/O
When an application issues a web request, it typically waits for a response before scheduling subsequent ones (e.g., 1, 5, 10… 30). Instead, we can perform non-blocking I/O, allowing the application to do other work while waiting—such as issuing additional requests.
In Python, this is achieved by scheduling functions as tasks within an event loop, commonly using the asyncio concurrent executor or any similar e.g. uvloop, anyio, FastAPI using anyio under the hood, and async/await constructs to denote asynchronous functions. In Go this functionality is baked directly into the runtime.
async def get_feature_batch():
async with aiohttp.ClientSession() as session:
# ~0.5s on MCB Pro M1
async with session.get(f"https://httpbin.org/delay/1") as response:
return await response.json()
async def prepare_feature_batch(preprocessing: bool = False, fraction_of_io: float = 0.0):
features = await get_feature_batch()
def perform_async(num_feature_batches: int, fraction_of_io: float):
async def tasks():
await asyncio.gather(*[prepare_feature_batch(preprocessing=True, fraction_of_io=fraction_of_io) for _ in range(num_feature_batches)])
asyncio.run(tasks())
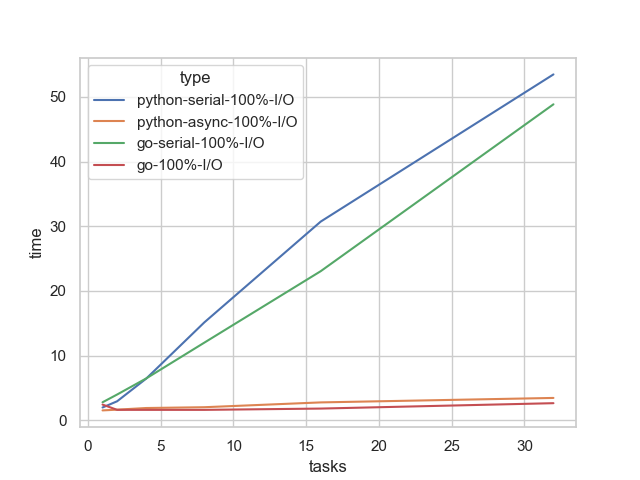
Both concurrent implementations scale significantly better, which is great. The trend is nearly flat because I/O operations are external, incurring minimal CPU work on the machine. This essentially means you can scale almost infinitely.
Under the hood, Go uses preemptive scheduling, where the event loop spends a maximum amount of time on each goroutine before switching to another, making it effectively non-blocking. In contrast, Python’s async-io is cooperative, meaning we return the control back to the event loop, while itself it goes to execute (potentially) another async function. Both implementations achieve non-blocking I/O.
Again, Go is a bit faster, since it’s a compiled language.1
3. What if it is not just I/O, but I/O + CPU?
As mentioned earlier, our application performs CPU-intensive work for each web call — either postprocessing or preprocessing. We shall assume that the CPU work accounts for half of the total duration of a single web request within a task.
def preprocess_feature_batch(iterations: int):
'''
This is a fake CPU operation that is used to simulate a CPU-intensive operation.
'''
def fake_cpu_op(iterations: int):
result = 0.0
noise = random.random()
for i in range(iterations):
result += (12345.6789 * noise ) ** 0.5 # Perform a CPU-intensive operation
fake_cpu_op(iterations)
async def prepare_feature_batch(preprocessing: bool = False, fraction_of_io: float = 0.0):
features = await get_feature_batch()
if preprocessing and fraction_of_io > 0.0:
loop = asyncio.get_event_loop()
# 15_000_000 / 0.8 ~= 1s on MCB Pro M1
# a good practice to use run_in_executor to run CPU-bound non-async tasks to not block the event loop
await loop.run_in_executor(None, preprocess_feature_batch, int(fraction_of_io * 15_000_000 / 0.8 * 2))
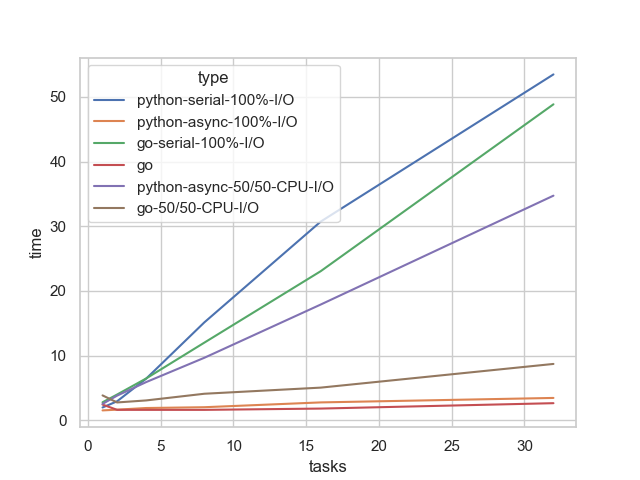
The situation easily becomes problematic for Python’s async implementation. Unlike I/O, CPU work must be handled by the machine itself - it’s not external work performed by some remote DB after all we are patiently waiting for. async-io implementations execute async code within a single thread, and on on top of that, GIL cripples any attempts at multi-threaded execution - something like Tokio or Deno can easily achieve. As a result, the async implementation with CPU work becomes nearly serial (observe the purple line approaching the green one) quite overshadowing I/O concurrency gains — no true parallelization happens.
In the Go implementation, we can see that the runtime nicely distributes the work across 8 cores, at least up until 8 tasks, and then it scales much more slowly than in Python. This demonstrates proper parallelization.
4. Existing Python paralelization techniques
We can only achieve true parallelization == multicore execution in Python with multiprocessing. It is also possible to spin-up async tasks in a separate process pool with loop.run_in_executor, but for simplicity reasons I just do it without async:
def perform_multiprocessing(num_feature_batches: int, fraction_of_io: float):
with ProcessPoolExecutor(max_workers=num_feature_batches) as executor:
futures = [executor.submit(prepare_feature_batch_serial, preprocessing=True, fraction_of_io=fraction_of_io) for _ in range(num_feature_batches)]
results = [future.result() for future in as_completed(futures)]
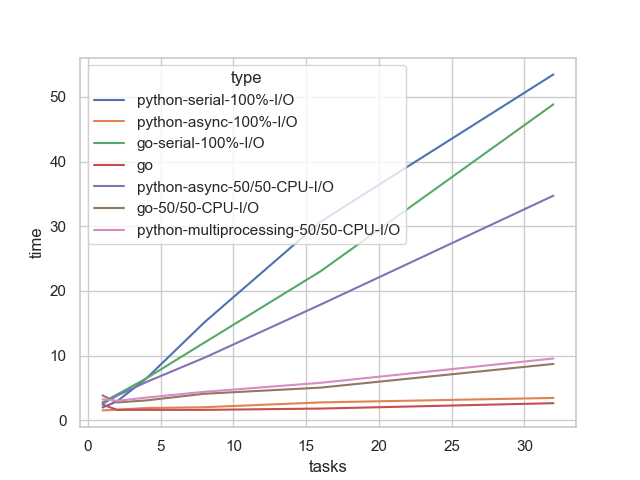
As we can see above, multiprocessing gets the job done and is as fast as its Go counterpart. Unfortunately, as mentioned earlier, multiprocessing has significant drawbacks:
- Inter-process communication relies on pickling, which is expensive for large objects.
- Copy-on-write, which can only be avoided with wizard-level tricks, such as ensuring the code references a data wrapper to avoid modifying the data’s reference counter.
- Spinning up processes is costly, and context switching worsens with more processes than cores, limiting you to a CPU-count pre-initialized pool (you have to manage it) and making many connection APIs is essentially unscalable.
It’s a massive pain.
5. No-GIL!
There is a Python free-threading version, 3.13t, which is not yet production-ready, but we can already experiment with it to see if we can achieve any gains with pure threading.
PYTHON_GIL=0 uv run --python 3.13t <...>
def perform_threaded(num_feature_batches: int, fraction_of_io: float):
with ThreadPoolExecutor(max_workers=num_feature_batches) as executor:
futures = [executor.submit(prepare_feature_batch_serial, preprocessing=True, fraction_of_io=fraction_of_io) for _ in range(num_feature_batches)]
results = [future.result() for future in as_completed(futures)]
return results
Why not use async? Unfortunately, asyncio and other event loops implementations do not yet support multi-threading mode.
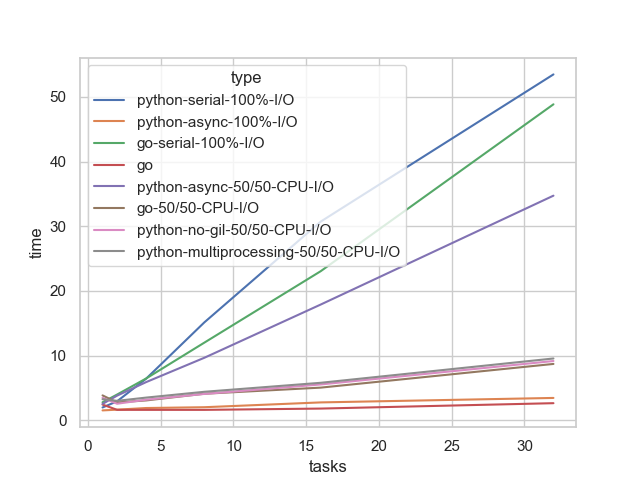
Wow! We get similar performance as with multiprocessing, without the tradeoffs. Unfortunately, we had to go back to lower-level threading constructs. As far as I know, there are no production-ready multithreaded event loop implementations yet. One very cool experimental project already exists, do check it out.
I remain optimistic about Python’s future. I believe No-GIL is a breakthrough for latency-sensitive apps where you still want to stay Pythonic. This is often the case for data science applications.
And, as always, never forget to benchmark.
1 Quite by accident, I noticed that I throttled Go implementation for IO+CPU experiments. I ensured Go spends exactly the same amount of time on CPU operations as Python, which resulted in Go doing many more iterations than Python. Multiple times I concluded Go is just a bit faster than Python, whereas it actually is astronomically faster. But that does not change my main point that without GIL, no matter however you slice your CPU-bound work into async blocks, you will not see any gains. Will adjust the post.